
- 数据收集系统架构设计要点
- chukwa(Apache)
- scribe(Facebook)
- flume(Apache)
- logstash
- kafka(Linkedin)
- TT(Timetunel)(阿里)
数据收集系统架构设计要点
(1)低延迟:从Log数据产生到能够对其做分析,希望尽可能快的完成数据的收集。在批处理或者离线分析中,对数据的实时性要求并不高,但是随着大数据的发展,实时计算的能力越来越强,实时分析的场景也越来越多,所以对日志收容的实时性要求也越来越高。
(2)可扩展:日志分布在服务器集群上,由于业务或者系统的原因,集群的服务器会发生变化,如上线,下线,宕机等,Log收集框架需要能够相应的做出变化,易扩展,易部署。
(3)容错性:Log收集系统需要满足大的吞吐以及承受足够的压力,这就意味着Log收集系统很可能面临宕机的风险,在这种情况下,Log系统需要有不丢失数据的能力。
chukwa(Apache)
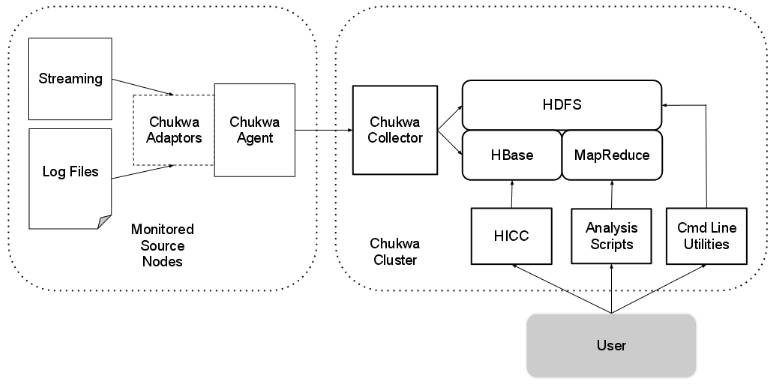
囊括了日志收集、数据分析、可视化等功能
scribe(Facebook)
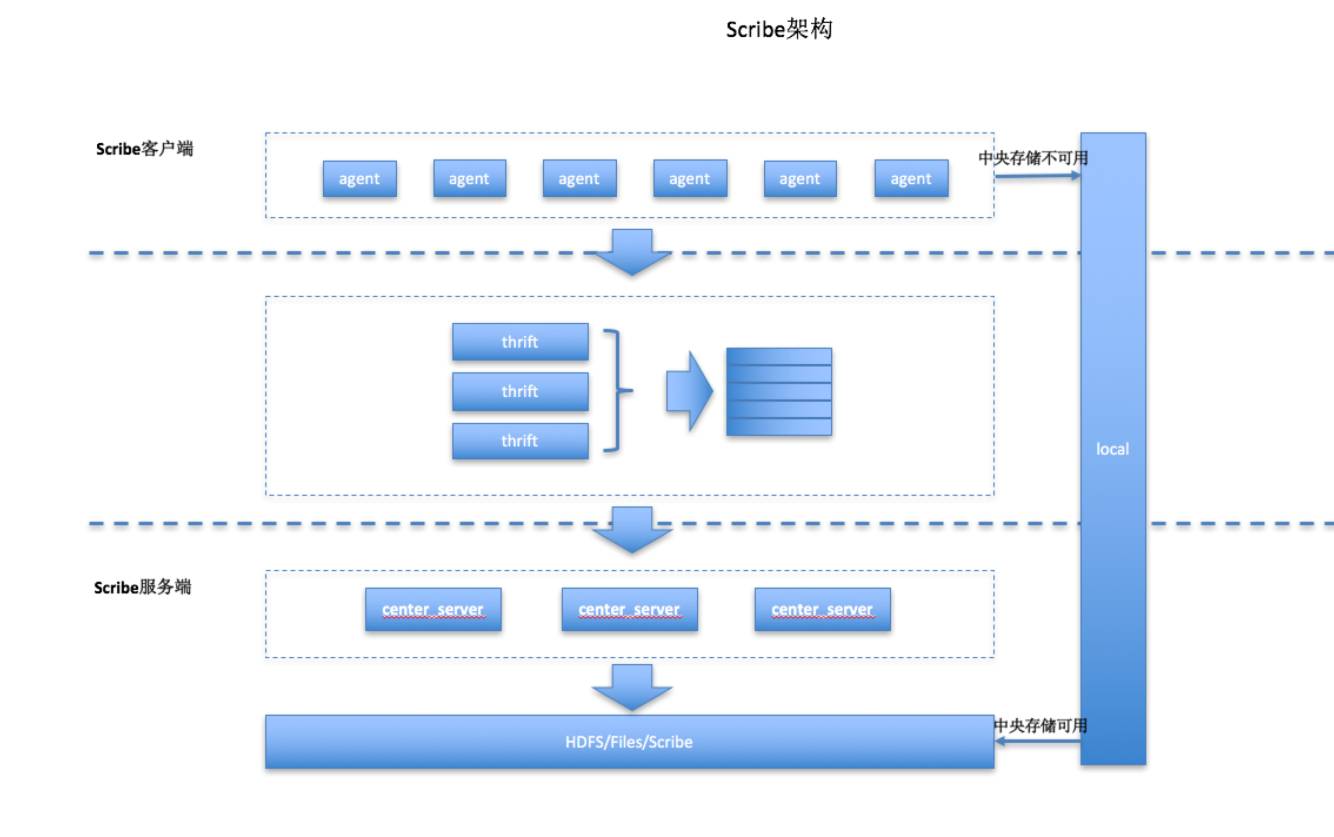
网络不通的情况下存储到本地,通了的情况下,还能重发,类似git
flume(Apache)
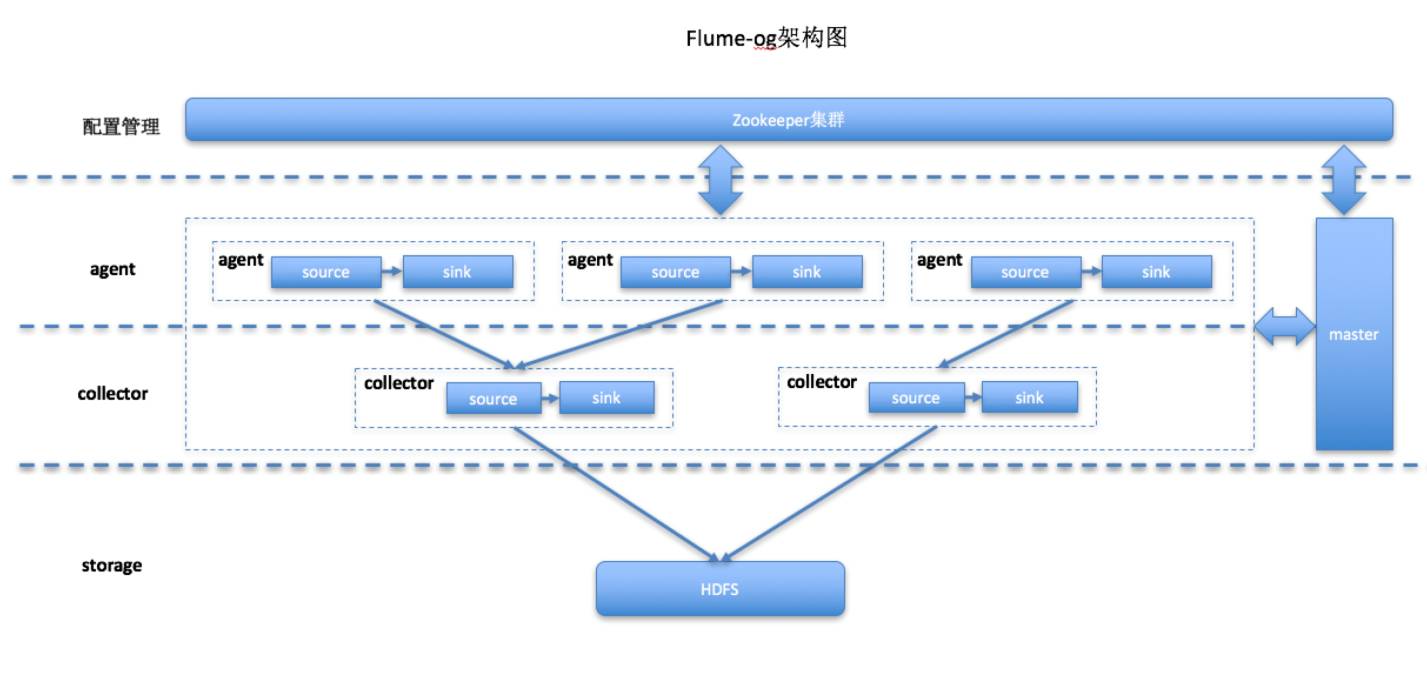
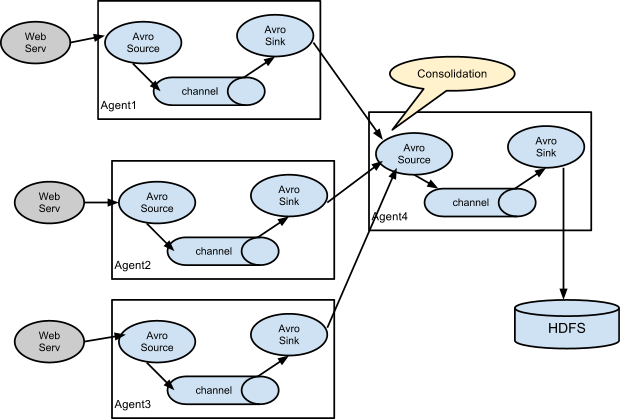
flume-ng:
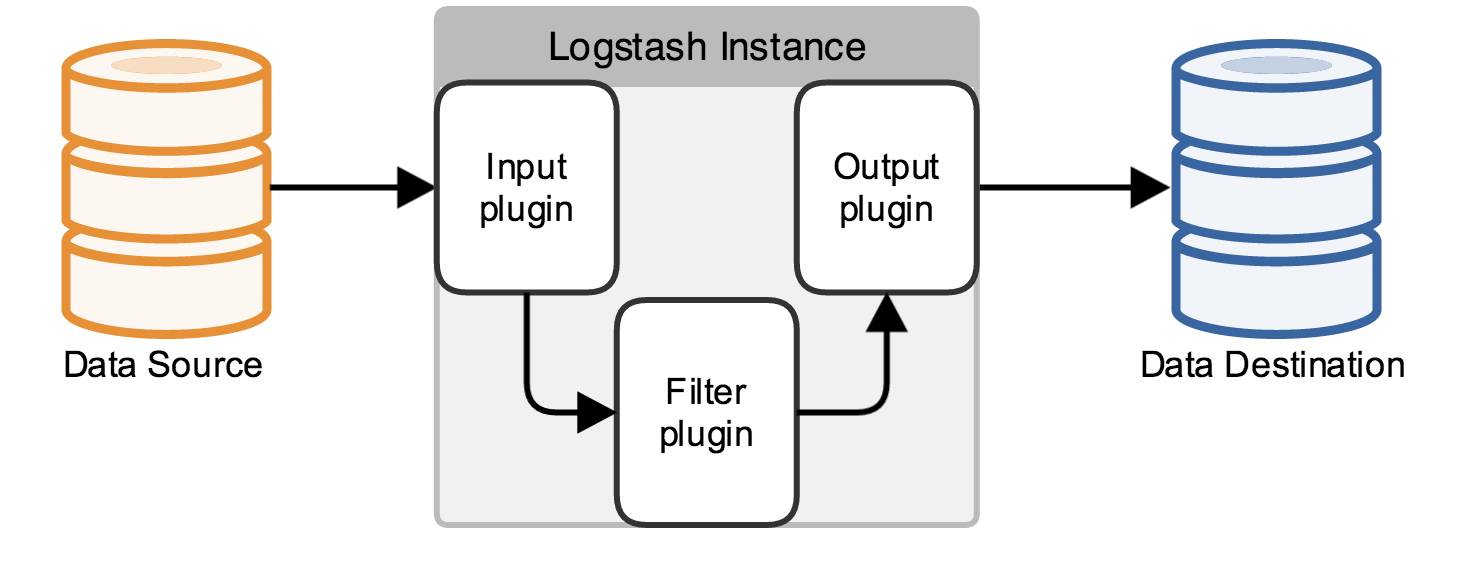
logstash
kafka(Linkedin)
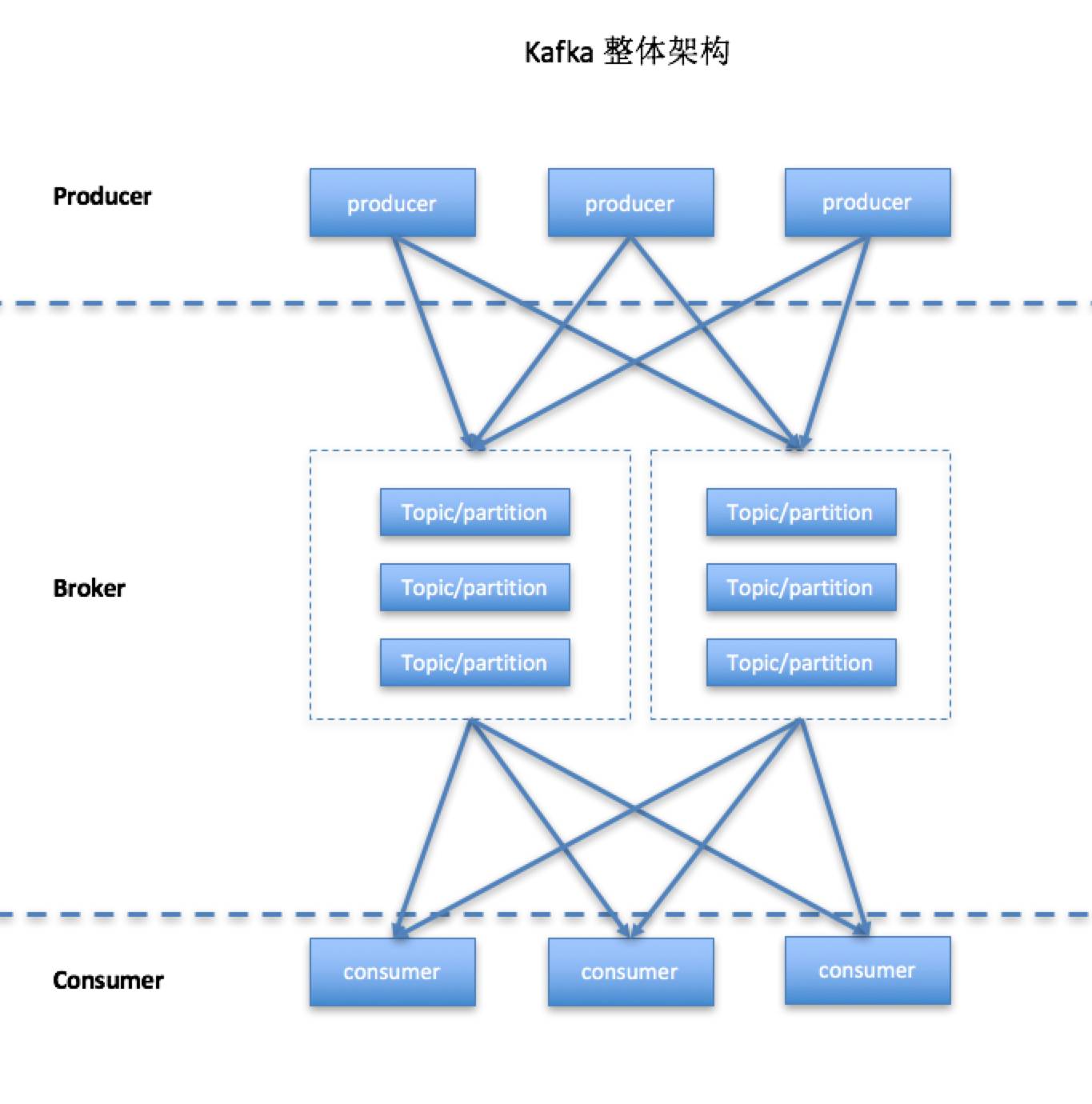
数据传输功能,非日志采集功能,大吞吐量
TT(Timetunel)(阿里)
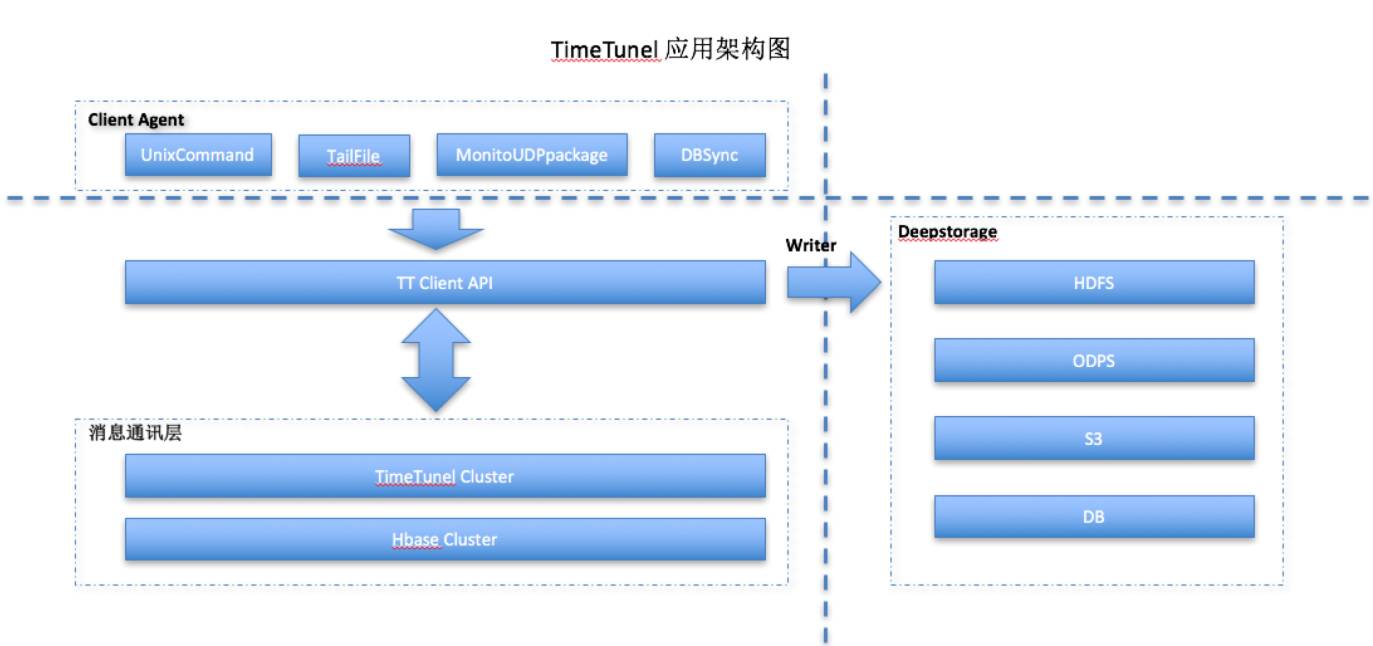
数据传输功能,非日志采集功能,大吞吐量




